Network Layer:overview
- data plane
데이터 평면
- control plane
제어 평면
라우터 내부에는 어떤 것들이 존재하는지
IP 프로토콜
SND, 포워딩
미들 박스
트랜스포트 계층에서 전달된 세그먼트를 받아서 받는 쪽으로 보냄
보내는 쪽에서는: 세그먼트에 네트워크 헤드 더해서 데이터그램으로 만들고 링크계층으로 전달하게 된다.
받는 쪽에서는 : 데이터그램에서 헤더읽고 처리후 세그먼트 빼내기, 그리고 트랜스포트계층으로 전달
네트워크계층은 중간에 라우터들에서도 존재한다.
이더넷 스위치(ethernet switch) <- 링크 계층에서 동작
스위치같은 경우에도 layer-2스위치, layer-3스위치가 았다
2는 링크계층에서의 스위치, 3이 네트워크에서 동작하는 스위치이다.
라우터가 하는 일은
네트워크 계층에서 동작하는데, 받은 데이터 그램의 헤더를 확인 후, 헤더 내용에 따라서 인풋포트에서 아웃풋포트로 데이터그램을 전송하는 역할을 한다. 주의해야할 것은 포트라는 용어인데, 포트는 TCP, UDP 트랜스포트에서는, 어떤 프로세스로 전달될 것인지를 알기위해서 사용했었는데
여기서는 다르다. 여기서 인풋,아웃풋 포트는 라우터를 보면 링크랑 연결되어있는 랜선이 꼽는 곳을 포트라고 한다.
여기서 말하는 인풋포트는 랜선 꼽는 곳이라고 생각하면된다.
이 포트에는 링크가 연결되어 있다. 포트를 정한다는 것은 어떤 링크로 데이터를 보낼지를 결정하는 것과 같다.
그러므로 링크와 포트 같은 의미로 사용된다.
네트워크 계층에서 제공하는 기능 2가지
- 포워딩
라우터에 인풋으로 들어온 패킷을 적절한 아웃풋으로 전달을 해주는 것
- 라우팅
전체적인 관점에서 포내는 쪽 코스트에서 받는 쪽 코스트까지 어떠한 경로로 패킷을 보낼지를 결정하는 것
여행계획을 짠다라고 했을 때, 포워딩은 분기점들마다 어떤 도로로 갈지를 선택하는 것이라면
라우팅은 전체적인 관점에서 출발지에서 목적지까지 어떤 경로를 따라 갈지를 결정하는 것이다.
네비를 찍으면 출발 ,도착지를 입력하고 어떤 최적의 경로를 알려준다. 이것이 라우팅이고,
운전을 해서 도로를 달리면 매번 분기점이 있을 텐데 이런 것들을 네비에서 알려주는, 이런 것이 포워딩이다.
포워딩과 라우팅이 네트워크 계층에서 굉장히 중요한 부분이다.
이것들이 결국 control, data plane과 정확히 매칭이 된다고 생각하면된다.
그래서 data plane은 각 라우터 관점에서 봤을 때 도착한 데이터그램을 어떤 인풋포트에서 아웃풋포트로 전달할 것인지를 결정하는 것이고,
control - 은 전체적인 관점에서 이동경로를 결정한다.
control- 2가지 방법이 있다.
1. 각 라우터별로 라우팅 알고리즘을 구현하는 방법, traditional routing algorithms
2. SDN(software-defined networking)
원격에 서버가 존재하고 그 서버에 라우터에서 수집한 모든 라우팅 정보를 이 원격 서버에 보내고 서버가 전체적인 정보들을 취합을 해서 전체적인 네트워크 상태를 알게되고, 이 상태를 고려해서 최적의 이동경로를 결정하는 것
원격의 서버에 이러한 라우팅 정보가 모이면 이 정보를 소프트웨어로 정의를 해서 경우에 따라 어떤 선택을 할 것인지를 sw로 결정할 수 있다.
전통적인 방법에서는 각 라우터에 구현이 되어 있기 때문에 라우터에 있는 소프트웨어를 수정할 수 없다. 하드웨어로 만들어져서 나오는 것이기 때문에. 그래서 자유롭게 할 수가 없는데,
SDN은 이와 반대로 자유롭게 할 수 있기 때문에 최근 각광받는 기술이라고 한다.
전통적인 방식이 각 라우터마다 라우팅 알고리즘을 구현하는 방식이고
각각의 라우터에 구현된 라우팅알고리즘컴포넌트가 존재하고 각각 포워딩 테이블들을 가지고 있다. 라우팅 알고리즘 컴포넌트들끼리 상호작용해서 업데이트를 한다. 알고리즘을 가지고 상호작용후 결과를 가지고 로컬 포워딩 테이블을 업데이트한다.
그래서 각 라우터 마다 있는 라우팅 알고리즘이 서로 상호작용하며 포워딩 테이블을 업데이트하니까 전체적으로 업데이트를 시킬 수 있는 control plane 역할을 하며, 각 라우터마다 있는 포워딩 테이블을 들어오는 데이터그램에 맞는 라우터로 가게 해주므로 포워딩 역할을 하는 data plane 역할을 한다.
전통적인 방식
각 라우터
라우팅 알고리즘 컴포넌트 --> 상호작용 -> 전체적인 포워딩 테이블 업데이트 --> 라우팅 --> control plane
포워딩 테이블 --> 데이터그램 헤더 확인 -> 각 데이터에 맞는 라우터 찾기 ---> 포워딩 --> data plane
SDN
원격에 컨트롤러 존재 == 서버
remote controllers == servers
서버들로 구성됨
각각의 라우터마다 포워딩 테이블을 가지고 있다.
remote controller도 포워딩 테이블을 유지하고 있고, CA(control agent)가 RC와 상호작용해서 라우팅 정보를 RC한테 알려줌. 이 원격에 있는 RC가 정보들을 종합해서 각 라우터에 최적의 포워딩 테이블을 만들어 내고, 업데이트를 해준다.
SDN
RC --> CA에 있는 라우팅 정보 받기 --> 전체 CA 테이블 업데이트 --> 라우팅 --> control plane
각 라우터
CA --> 포워딩 테이블 RC로 보내기 --> 업데이트된 테이블 받기 --> 포워딩 --> data control
네트워크 계층에서 제공하는 서비스 모델에는 어떤 것들이 있나
각각의 데이터그램 관점에서 몇가지 예시를 생각해보면
한번 보낸 데이터그램이 무조건 목적지에 도착하는 것 보장?
제한 시간 이내에 도착?
데이터 그램의 흐름 관점
순서가 바뀌지 않고 도착?
최소한의 대역폭을 보장?
연속적으로 패킷을 보낸다면 inter-packet spacing 은?
위 질문을 기반을 굉장히 많은 서비스들이 존재할 수 있을 것이다. 그러나 중요한 것은 실제로는 기본 네트워크 계층 서비스 모델은 Best effort서비스 모델을 사용한다.
BE는 최선은 다하지만 아무것도 보장하지 않는다는 의미 == no guarantee
대역폭, 패킷 손실, 패킷 순서, 지연 시간에 대한 보장 모두 하지 않는다.
인터넷은 기본적으로 Best effort 모델이다.
BE말고도 많은 서비스 모델들이 제시가 되었고 대체제가 있지만, 계속 internet을 사용하고 있다.
왜냐..
아무것도 보장하지 않기 때문에 복잡하게 동작할 필요가 없다 -> 동작 방식 간편
일정 수준 대역폭 보장이 된다면, 예를 들어 넷플릭스 등의 실시간 어플리케이션에 있어서도 충분한 성능을 제공할 수 있다.
이미 이렇게 실시간 어플리케이션에서도 BE 모델이 잘 동작하고 있기 때문에 굳이 다른 서비스 모델을 지원할 필요성 x
어플리케이션 계층에서 복제, 분산 서비스를 제공한다. ex. 데이터 센서 DNS 등
이렇게 추가적인 어플리케이션 계층에서 지원하는 것들로 인해서 결국에는 클라이언트가 가능한 가까운 서버에서 서비스를 제공받을 수 있게된다. 상대적으로 지연 시간 같은 것에서 자유로울 수 있다. 그래서 이러한 보장 없이도 낮은 지연 시간을 보장 받을 수 있게 된다.
네트워크 상위 계층에서도 네트워크를 낭비하고 있는 것이 아니라 congestion control 같이 최선의 노력을 하고 있기 때문에 네트워크 계층에서 BE 모델을 사용하더라도 문제없이 작동할 수 있다.
결국에는 BE모델을 써도 지금까지 잘 동작해왔기 때문에 굳이 바꾸려고 하지 않았다.
그리고 이런 모델이 네트워크 철학과 더 맞다.
네트워크 엣지부분에 스마트하고 복잡한 것들을 놓고 중앙에는 단순, 간단 한 처리 할 수 있는 것이 기본 철학이므로
위와 같은 보장이 되는 모델들을 상위 계층에서 하는 것이 더 맞다.
라우터 안에는 어떠한 것들이 있는지
라우터의 전체적인 개요를 보면
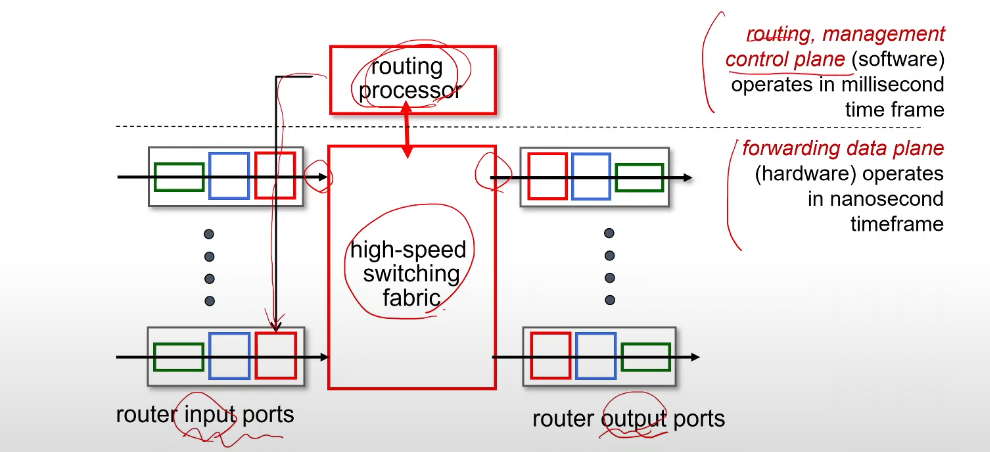
인풋 포트가 있고 아웃풋 포트가 있다.
중간에 스위치 구조가 있다. 이 둘을 연결시켜주는 역할을 한다.
그리고 routing processor있고, 이는 CPU역할을 한다. 얘같은경우에는 이제 control plane의 역할을 수행한다
라우팅 프로세서가 결국에는 포워딩 테이블 같은 애들을 업데이트해준다.
그리고 라우팅 프로세서가 라우팅 부분인 control plane, 그 아래 스위칭 구조가 forwaring data plane 이다.
프로세서는 일종의 CPU로 소프트웨어를 실행할 수 있다. 실제로 컨트롤 플레인은 어느정도 소프트웨어위에서 돌아간다. 대신 라우터 안에있는 라우터가 만들어질 때부터 포함이 되어 있는 소프트웨어이다.
포워딩을 처리하는 스위칭 구조는포워딩을처리하는데 기본적으로 하드웨어적으로 구현이 된다.
그래서 하드웨어적으로 구현된 아랫부분이 더빠르다.
그래서 소프트웨어적으로 구현된 것 위에서 돌아가는 라우터 프로세스는 밀리 세컨드 정도가 걸리고,
하드웨어적으로 구현된 스위칭 구조는 하나의 포워딩을 처리하는데 나노세컨드 정도 걸리며
따져보면 백만배로 굉장히 많은 차이가 난다.
입력포트 같은경우에는 여러경우를 수행하는데,
일단 위 그림에서 보이는 초록색부분은 line termination으로 물리계층의 역할을 수행한다.
그래서 라우터가 물리계층, 링크 계층, 네트워크 계층 3가지계층의 역할을 수행을한다고 했는데. 이중에서 물리계층이 가장 바깥쪽에 있다. 잇풋이기 때문에 외부에서들어로는 것.
이 물리계층을처리하는 부분이 가장 바깥쪽에 있고 얘는 비트단위로 신호를 받으면 신호를 변환해서 다음 계층에 전달을 해준다.
그게 링크 계층이라고 생각하면 된다.
그다음에 파란색인 link layer protocol 인 링크 계층이 존재를 하고, 이더넷 같은 것을 떠올리면된다.
그리고 네트워크 계층의 일을 처리하는 빨간색 컴포넌트 looKup, forwarding queueing 이 존재한다.
헤더에 있는 필드를 확인하고 라우터 메모리에 포워딩 테이블을저장하는데, 포워딩테이블에서 어떤 아웃풋 포트를 선택을 해야하는지를 탐색을 해서 정하는 일을 하는것이 이 컴포넌트의 역할이다.
여기서 중요한 포인트는 링크가 제공하는 스피드가 있을 것인데, 이를 보통 라인 스피드라고 한다. 물리적인 링크의 스피드라고해서 이 속도를 다 낼 수 있다면 '라인 스피드를 낼 수 있다' 라고 표현한다.
그래서 가장 중요한 것은 이 라인 스피드를 만족할 수 있는지 이다. 들어오는것이 굉장히 빠른데, 이중간에서 처리하는게 느리다고 생각을 하면 패킷이 다 지연될것이고, 인풋 포트 큐잉 같은것이 발생할 수 있다.
그래서 이것을 굉장히 빠르게 처리하는 것이 중요한 포인트이다.
그래서 스위칭 구조가 하드웨어로 구현되는 것이다.
하드웨어로 구현되어야만 빠른 속도로 제공할 수 있기 때문에
기본적으로 포워딩은 크게 두가지 방식이 있다.
단순히 목적지의 IP주소만 보고 포워딩을하는 전통적인 방식의 목적지 기반 전달 방식이 있고(Destination-based forwarding),
헤더의 목적지 ip 주소 말고도, 다른필드들을 참조해서 포워딩을하는 일반적인 전달방식이 있다.
👇👇빨간색 컴포넌트에서 하는 일 - 포워딩 👇👇
Destination-based forwarding
32비트 아이피 주소를 가지고 있다고 가정하면, 표현할 수 있는 아이피 주소는 2^32개의 IP를 나타낼 수 있고, 40억개정도를 나타낼 수 있는 양이다.
하나의 포워딩 테이블의 하나의 엔트리가 4바이트라고 가정해보자. 이보다 더 크겠지만,
1. 모든 IP를 갖고 있는 방법
이 때 4바이트라고 가정하고 계산을 해보면, 2^32 * 4
에서 2^30이 1gb이므로
= 2^30 * 4 * 4
= 16 * 1gb
= 16gb
결국에 16기가바이트가 필요하게 된다. 단순히 모든 ip 주소에 대해서 링크의 인터페이스를 포워딩 테이블을 만들려면
그 16기가바이트만큰의 메모리가 필요하게 된다.
그러나 이렇게 하면 모든 라우터마다 16기가바이트 만큼의 메모리를 가져야 하기 때문에 이는 너무 과하다고 판단할 수 있다.
사용하는 pc보다도 더 많은 메모리이다.
2. RANGE를 이용하는 방법
그러면 또다른 방법을 생각해보면 range를 활용하는 방법이 있을 수 있다.

위와 같은 상황은 이상적인 상황이다. 보면, 레인지가 잘 나눠져 있어서 서로 겹치지 않는 상황이다.
그래서 위 테이블 1번 같은 경우는 0번 아웃풋 링크로 전달을 하고,
아래는 1번으로, 2번으로,.. 이렇게 표현할 수 있다.
이렇게 잘 나뉘어질 수 있는 상황이 아니라면,
예를들어 라우팅 알고리즘에 의해서 포워딩 테이블이 업데이트 되었다고 가정해보자.

그래서 지금과 같은 상황이 되었다고 가정하면,
원래는 0번 아웃풋 링크로 가야했던 상황에서 새로운 레인지가 생겼다고 한다면 100 - 111까지는 3번 인터페이스로 가야한다.
이렇게 되면 0번아웃풋 링크로 가야하는 레인지가 3번 아웃풋 링크로 가야하는 100-111까지를 포함하게 되기 때문에 복잡해진다.
이를 해결하기 위해서는 0번 아웃풋 링크로 가야하는 레인지를 다시 쪼개서 00010000 00000000 - 10000 00000011 레인지를 추가로 만들고 3번 아웃풋으로 가는 100-111까지인 레인지 뒤에
00010000 00000111 - 00010111 11111111 까지 0번 아웃풋 링크로 가는 레인지를 다시 만들어 준다.
이런식으로 만들 수도 있지만 , 더 쉽게 해결하는 방법이 존재한다.
3. Longest prefix matching
suffix - 접미사
prefix - 접두사
그래서 포워딩 테이블 엔트리를 검색할 때 가장 긴 주소를 나타내는 프리픽스를 사용해서 이에 해당하는 아웃풋 포트를 결정한다.
이에 해당하는 예시이다.

위와 같이 표현할 수 있다. 위 2번방법보다 간단하다. *표시가 된 것은 정해지지 않은 숫자들이 주소 레인지에 포함되어 있는 것이다.
이러한 ip가 주어졌을 때 어떤 링크 인터페이스를, 어떤 링크를 선택해야하는지 주어진 주소들과 매칭을 해볼 수 있다.
그러나 매칭가 중복된 애들이 있을 수 있는데, 여기서 어떤 걸 선택하는지의 기준은 LONGEST PRIFIX, 즉, 가장 매칭이 정확하게 맞는 부분이 긴 레인지를 선택해주면 된다.
예를 들어 11001000 00010111 00011000 ----- 이런 IP 주소가 있다고 한다면, 1번 아웃풋, 2번 아웃풋 링크 모두 매치되지만, 그중에서 가장 긴 프리픽스인 1번 아웃풋 레인지를 선택하면 되는 것이다.
이 방법같은 경우에는 소프트웨어로 하지는 않고, 하드웨어로 구현된다.
프리픽스를 매칭하는 것이 쉽지는 않을 것이다.
그래서 사용되는 것이 TCAM이라고 해서 어떤 컨텐트(내용)을 주면 그 내용을 메모리에서 찾아서 리턴해주는 종류의 메모리이다.
그래서 이와 같은 방법 같은 작업에 최적화 된 메모리라고 할 수있다.
이 TCAM이 주어졌다고 하면여기다가 IP주소를 넘겨주면 그 IP 주소에 해당하는 포트를 계산을 해서 빠른 속도로 한 클럭 사이클 만에 주소 탐색을 해준다. 그리고 이와같은경우에는 하드웨어적으로 벙렬적으로 체크하기 때문에 테이블 사이즈와 관계없이 프리픽스를 찾을 수 있다.
Cisco catalyst
시스코 같은 경우에는 스위치 스위치를 만드는 회사인데 약 1M개의 테이블 엔트리를 지원할 수 있는 TCAM 지원
👆👆 여기까지 DESTINATION-BASED FORWARDING 👆👆
👇👇 Switching fabrics 👇👇
스위치 구조가 하는일은 인풋포트에서 들어온 패킷을적절한 아웃풋 포트로 전달을 해주는 역할을 한다.
작업을 얼마나 빨리할 수 있는지가 Switching rate이다.
N개의 인풋이 있다면, 이 N개가 모두 스위치 구조를 공유를 하니까 각각의 링크가 R이라는 링크 RATE를 가지고 있다고 하면 스위치 구조는
N * R만큼의 스위칭 Rate를 지원해 줄 수 있어야만 한다.
그렇기 때문에 가장 좋은 것은 들어오는 애들보다 더빠른 스위칭 rate을 가져야한다.
관련해서 스위칭 구조 같은 경우에는 여러가지 방식이 있다.
- 메모리를 활용하는 방식
- 공유 버스를 활용하는 방식
- 인터 커넥션 네트워크 방식
👉 메모리 활용 방식
메모리를 활용한 방식이 가장 최초에 나왔던 라우터 방식이다.
간단히 생각해보면, CPU를 가진 일반 운영체제에서 인터럽트를처리하는 것을 떠올려보면,
라우터의 CPU 라우터 프로세스가 인풋 포트에 어떤패킷이 도착하면,
라우팅 프로세서한테 인터럽트를 준다.
그러면 라우팅 프로세서가 이패킷을 메모리로 카피를 한다. 그 다음 카피된 내용을 아웃풋 포트로 다시 카피를 해준다.
카피를 2번을해야하기 때문에 메모리 Bandwidth보다 1/2로 나눈 것 만큼 전체적인 성능이 저하된다.
카피와 버버링이 된다.
👉 공유 버스
버스라고 하면 데이터가 지나갈 수 잇는 통로라고 생각하면 된다.
그래서 이 구조에서는 공유한다고 했으므로,
패킷이 도착했을 대 버스까지 전달을하고 버스에서 어느 아웃풋으로 가야할지 라벨링을 해서 버스에 태운다.
태운 패킷이 버스따라 가다가 가야할 라벨이 있는 포트로 전달되는 것이다.
공유를 하다보니까 버스가 높은 밴드위스를 제공해야 병목현상이 발생하지 않을 수 있다.
일반적으로 버스의 대역폭을 크게 잡아야하고, 원래도 이러한 구조의 라우터에서는 충분한 대역폭을 제공한다.
그렇기 때문에 콘텐션 관련된 문제는 그렇게 크게 발생하지 않는다.
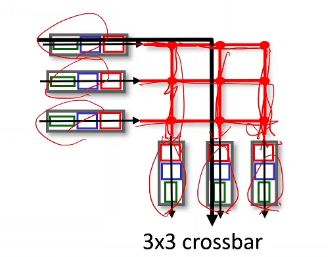
👉 인터커넥션 네트워크
크로스바 방식: 기본적으로 멀티 프로세서, 여러개의 CPU가달린 구조에서 원래 사용하기 위해서 만들어진 방법.
그물망 모양으로 네트워크가 인풋과 아웃풋 링크들이 이어져있고, 어떤길로도 인풋과 아웃풋이 연결되어 있다.
멀티 스테이지 스위치 방식: 스테이지를 여러개 나눠서 단계별로 처리하는 것을 의미한다. 기본적으로 병렬화를 활용한다. 데이터 그램을 특정한 사이즈로 조각들로 쪼개서 한번에 보내고 이것을 반대쪽 받는 쪽에서 다시 조립을 하는 형태


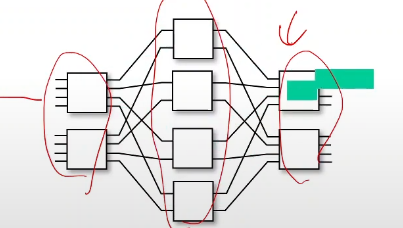
좀더 나아가면 이러한 멀티 스테이지들 플랜들을 여러개 두어서 상황에 따른 스테이지를 활용하는 방법도 있다.
이렇게 병렬화 함으로써 더 높은 성능 제공 가능
이러한 모델은 비쌋 라우터에서 구현할 수 있다.
👆👆 스위칭 패브릭 👆👆
👇👇 Queueing 👇👇
그리고 QUEUEING
큐잉은 여러군데에서 발생할 수도 있다.
인풋, 아웃풋 포트 모두 가능하다.
인풋 포트 부터 보면
인풋 포트에서 발생할 수 있는 상황은,
모든 인풋포트의 성능을 다 더한 속도보다 중앙 스위칭 구조가 더느리면 큐잉이 발생할 수 밖에 없다.
인풋 큐에서 큐잉이 발생해 딜레이가 발생할 수 있기 때문에 로스가 발생할 수도 있다.
HEAD of the line(HOL) 줄에 맨 앞에 있는 애가 block 된것을 의미
여러 인풋에서 똑긑은 아웃풋으로 보낸다고 할때, 이 스위칭 구조가 만약에 인터커넥트 네트워크라고 한다면,
이 출력 포트가 같을 때에는 동시에보낼 수가 없다. 그렇기 때문에 동시에 보내게 되면 다른 애는 기다려야한다.
먼저 도착한 애가 블락되어 뒤에 있는 애가 기다리는 상황을 이야기 한다.
아풋풋 포트쪽에서도 큐잉이 발생할 수 있다.
스위치 구조쪽에서 들어오고, 나가는 쪽을 R이라고하자
스위치 구조가 나가는 속도보다 바르면 큐잉이 발생하게 된다.
그렇기 때문에 버퍼링을 해야한다.
근데 만약 공간이 없어 버퍼링할 수 가 없다면
무언가는 버려야하기 때문에 드랍관련 폴리시가 존재해야하고,
이런 상황에서의 패킷 손실이 존재할 수밖에없다.
드랍 폴리싱-> 어떤 애를 트랜스미션을 먼저할 것인지에 대한 규칙들도 있을 수 있다.
이런 경우에는 어떤 애들이 더 높은 성능을 보낼지 우선순위 기반으로 스케쥴링 해서 어떤 애한테 높은 우선순위를 줄 것인지 정할 수도 있고,
네트워크 neutrality라고 해서, 네트워크는 만인에게 평등해야한다.라는 의미
똑같은 조건으로 전달이 되어야 한다는 개념
결국 더빨리 들어오면 버퍼링을 해야한다는 얘기
아웃풋 포트에 있는 버퍼가 결국에 오버플로우가 나면 큐잉딜레이도 발생할 것이고, 패킷로스도 발생할 수 있다.
버퍼링을 어느정도 유지를 해야 좋을까?
RFC에 정의된 바에 의하면 Rule of Thumb 이 최선의 방법이라고한다.
이런 경우 버퍼의 크기를 계산해보면, rtt * link의 capacity 만큼의 버퍼링을 요한다.
최근에 업데이트된 것에 의하면 이를 다시 루트 n으로 나눈만큼이라고 한다.
RTT * C / root N
패킷로스가 날 수 있었던 상황에서 한번더 버퍼링함으로써 기회를 준것인데. 이 버퍼링이 딜레이를 만들 수 있다.
그래서 이 버퍼링을 너무 크게 잡다보면 RTT가 길어질 우려가 있고, realtime app 같은 경우 성능, 리스폰스 느려질 수 있다.
delay-based congestion control 이라고 해서 혼잡하지 않은 상황에서의 최고의 성능이 나오도록 계속 유지를 하는 방법
이것 보다 떨어지면 센딩 레이트를 줄여서 적당히 항상 FULL할 만큼을 채우되 넘어서지 않는 만큼만 유지를 하는 것이 최선이라는 방법으로
버퍼링을 많이하는 게 좋은것만은 아니다.
Buffer Management
아웃풋에서 버퍼,
이 버퍼에서 큐잉을 하게되는데 이를 간단히 생각해보면 중간에 큐가 있는 것과 다를게없다.
큐와 디큐를 이용해 다음단계로 넘겨주는 것이다.
이상황에서 어떤 패킷을 추가를하고, 어떤 패킷을 버릴 것인지 (버퍼가 꽉찼을 때)
이러한 폴리시가 필요하다.
테일드랍: 막 도착한애를 그냥 버리를 방법
프라이오리티: 우선순위를 정해서 기존에 있던애와 새로운 패킷 비교해서 어떤 애 버릴 건지 경정하는 방법
마킹방법: 위에서 배웠었는데 congestion control을 네트워크의 도움을 받아서 처리를 하는 ECN이 있었다. 라우터에서 이 기능을 제공을 해야한다. 이같은 경우 라우터 쪽에서 컨제스천 상황을체크해준다.
👆👆 Queueing 👆👆
👇👇 패킷 스케줄링 👇👇
패킷 스케쥴링
어떤 패킷을 다음에 보낼지를 정해야하는데, 많은 종류의 스케쥴링 방법이 있다.
- First come, first served
- priority
- round robin
- weighted faire queueing
- first come, first served
FCFS
FIFO라고도 한다.
먼저들어온 애가 먼저 아웃풋 포트로 나간다.
- priority
패킷들이 들어온다고 햇을 때 분류를 한다.
헤더를 참조를 해서 할 수도 있고,,
여기서 헤더를 참조해서 어떤 것이 우선순위가 높고 낮은지를 분류한다.
높은 우선순위를 갖는애가 높은 우선순위 애들을 담는 버퍼에 쌓이고,
낮은 우선순위를 갖는애가 낮은 우선순위 애들을 담는 버퍼에 쌓일 것이다.
항상 높은 우선순위 버퍼에서 맨 앞에서 부터 순서대로 링크를 내보낸다.
같은 버퍼안에서는 FCFS 방식으로 동작한다.
높은 우선순위 버퍼가 차있는 한은 여기서 먼저 꺼내 링크로 보낸다.
낮은 우선순위 애가 먼저 도착했었더라고 걔는 냅두고 높은 우선순위 버퍼에 있는 것을 우선 보내고, 높은 우선순위애들이 버퍼에 없으면 낮은 우선순위 버퍼에서 꺼내서 보낸다.
- Round robin
돌아가면서 스케쥴링을 한다는 의미
비슷하게 여기서 헤더를 보고 분류를 한다.
각 분류한 버퍼에 있는애들이 단순히 돌아가면서 앞에서부터 하나씩 버퍼에서 끄내서 내보내는 방식이다.
우선순위의 문제는 높은 우선순위 버퍼에 계속 쌓여있다면 낮은 애들을 계속 실행할 수없겠지만,
라운드로빈은 어쨋든 돌아가면서 하나씩 처리하니까 그런 문제는 없다.
여기서 좀더 나아간게
- weighted fair queueing (WFQ)
이 방법 같은 경우에는 라운드 로빈을 일반화한 것이라고 생각하면 된다.
똑같이 헤더를 보고 분류를 하고,
라운드 로빈은 무조건 한번씩 번갈아가면서 내보냈는데,
얘는 여기서 가중치를 부여한다.
각 버퍼마다
예를들어 3개의 버퍼가 있고 각각 가중치가 4, 2, 1이라고 한다면 7번중 4번은 1번 버퍼에서 처리하고, 2번은 2번 버퍼에서 처리.. 이런식으로 동작하게 된다.
그래서 결과적으로 하나씩 돌아가면서 처리하지만, 높은 가중치를준애가 좀더 많은 패킷을 처리하게 된다.
👆👆 패킷 스케쥴링 👆👆
IP: the Internet Protocol
- datagram format
- addressing
👉 중요 포인트 👈
IPv4 format
IPv4 -> 10진수로 표현 8비트씩 .으로 나뉜, 서브넷 마스크
DHCP
Network Layer: Internet
호스트와 라우터 둘다 네트워크 계층을포함한다.

그리고 호스트 같은 경우에는 네트워크 레이어를 기준으로 위쪽으로 어플리케이션 계층과 트랜스포트 계층 까지 포함하지만
라우터는 그 아래로만 포함한다.
네트워크 계층에서 하는 일은 라우팅 알고리즘을 통해서 포워딩 테이블을 적절하게 업데이트를 시켜주고 포워딩 테이블을 참조해서 패킷을 적절하게 포워드 링크로 내보내는 것.
인터넷이랑 ip네트워크계층에서 핵심적인 역할을하는 IP프로토콜.
ip라는 말자체가 인터넷 프로토콜이다.
데이터 그램에 포맷이 어떻게 되는지.
주소는 어떻게 구성이 되는지.
👇👇 ICMP 프로토콜 👇👇
네트워크 계층에는 ICMP라는 프로토콜이 존재한다.
IP프로토콜에 포함이 되어 있다고 생각하면 되는데.
ICMP같은 경우에는 Internet control message protocol 의 약자이다.
TCP와 IP 조합, TCP IP를 통해서 패킷을 전송하려고 한다고 가정하자.
보낸 패킷이 경로상의 라우터들을 거처서 라우터를 따라서 패킷이 전달이 되다가
어떤 라우터에 도착을 했을 때 가는 길이 없어졌다, 라우터 테이블을 뒤저봐도 IP주소로 갈 수 있는 아웃풋 링크가 존재하지않는다면
TCP같은 경우에는 Reliable 전달 보장해준다.
도착이 될 때까지 계속 retransmission을 해줄 것이다.
도착할 수 없는 이 패킷은 불필요하게 계속 재전송을 한다면 중간 네트워크 상이 혼잡해 질 것이다.
이럴 때 사용되는 것이 ICMP프로토콜이다.
에러를 보호하는데 사용이 되는 프로토콜이라고 보면된다.
어떤 특정 라우터에서 네트워크 문제로 패킷을 목적지로 포워딩 할 수 없다면
에러 메시지를 만들어서,
원래 메시지를 보냈던 센더한테 에러메시지를 전달해준다.
센더 측에서는 문제가 생겨 패킷을 보낼 수 없음을 알려준다.
이러한 상황을 위해 ICMP 프로토콜이 사용된다.
👆👆ICMP 프로토콜 👆👆
👇👇 IP Datagram format 👇👇
ip 버전 4에 해당하는 데이터그램

ip버전은 크게 2가지이다.
IPv4, IPv6가 있다.
이둘의 데이터크램 포맷은 다르다. 이를 구별하기 위해 v로 나눈다.
- ver
필드를 확인을해서 버전값이 4면 IPv4이고
값이 6이면 IPv6이다.
- head len
bytes
그리고 가지고 잇는 필드의 헤더의 길이를 나타내는게 있다.
payload data 위까지가 모두 헤더인데, 여기 option으로 들어갈 수 있는 것들이 존재한다.
그래서 옵션으로 들어가기 때문에 헤더의 크기가 가변적일 수 있다.
그래서 가변적일 수 있기에, 헤더의 길이가 필요하다.
이것을 통해서 페이로드, 실제 데이터 부분의 시작점을 가리키는 역할을 한다.
- length
bytes
전체 데이터그램의 길이를 나타내는 것도 있다.
헤더의 길이가 아닌 전체의 길이를 나타내며,
이론상으로는 최대 64 키로바이트까지 이 데이터그램의 길이가 커질 수 있다.
실제로는 1500 바이트보다 작게 사용한다.
- type of service(TOS)
서비스별로 데이터그램을 다르게 처리하고자 할때 필요한 필드
앞에서 우선순위에 따라 어떤 패킷을 먼저 처리할지 를 정할 수 있다고 했는데,
실시간 어플리케이션과 관련된 트래픽인지, 실시간 아닌 트래픽인지 구분할수 있게 된다.
어떤 패킷은, 페이스타임처럼 실시간 빠르게 처리해야하는 패킷일 수 있고,
FTP 처럼 이와 반대되는 트래픽인지 구분할 수 있게 된다.
--> 지연시간이 중요한 것을 우선처리할 수 있게 하는 등의 값을 활용할 수 있다.
그리고 앞쪽의 0비트부터 5비트까지는 서비스를 나타내고
뒤에 두비트는 TCP쪽에서 다뤘듯이 Congestion control에서 네트워크 어시스트, 네트워크의 도움을 받아서 컨트롤할 수잇는 방법이 있다고 했는데,
이는 밑에쪽에 라우터에서지원을 해야한다고도 했다.
이에 대한 두비트이다.
라우터가 혼잡상황이라면 이 두비트를 체크해서전달해준다.
- TTL
네트워크 상에서 데이터그램이 무한히 순환하지 않도록 보장해주는 역할을 한다.
패킷을 보냈는데, 라우팅결과에 따라서 포워딩이 되는데,
이러한 과정에서 목적지를 못가고 루프가 발생하는 경우,
이러한 문제를 해결하기 위함
패킷을 보내는 쪽에서 이를 세팅해서 데이터그램을보내게 된다.
예를들어 64로 설정했다고 한다면,
매번 라우터를 거칠때마다 라우터에서 이 값을 1씩 줄여준다.
64 -> 63 -> ...
이게 0이된다면,
0이 되는 순간 라우터는 패킷을 포워딩하지 않고 이 패킷을 폐기처분하게된다.
이 값은 운영체제마다 또 다 다르다.
- upper layter protocol
네트워크 계층의 위쪽레이어라면 프랜스포트 계층이다.
내 위쪽에 있는 계층이 어떤 프로토콜을 쓰는지 나타내는 필드이다.
TCP, UDP 두개 밖에 없다.
트랜스포트레이어같은 경우에는 라우터에서는 필요가 없다. 존재하지 않는다.
이 필드를사용하는 곳은 메시지가 패킷이, 목적지에 도착했을 때, 목적지 호스트에 도착했을 때
네트워크 계층에서 트랜스포트 계층으로 전달을 해줄 때
TCP로 보내야하는지 UDP로 보내야하는지결정할때 사용한다.
- Fragmentation/reassembly
데이터그램이 있으면 64키로 바이트까지 가능하다고 했는데
이런 데이터그램을 내 밑의 레이어, 링크 계층에서
한번에 보낼 수 있는 양이 예를 들어 1500보다 더 작다고 한다면
64 키로바이트로 못보낼 것.
그렇기 때문에이 패킷을 쪼개야한다.
이를 fragmentaion, 단편화라고한다.
이렇게 단편화를 한다음에 리어셈블리는 다시 합치는 조립을 한다.
이 두개가 짝을지어 동작을 한다.
값같은 경우에는 id와 flag, fragment offset이 있음
- header checksum
전송과정에서 잘 전달 되고있는지확인가능
- source IP address, destination IP address
32 bits
- opstions
IPv6는 없어졌다.
거의 사용되지 않는다.
여기에는 timestamp, 어떤 경로를 따라서 전송되었는지 기록 등
다양한 방식으로 옵션을 사용할 수 있다.
옵션을 뺀 헤더 길이는 20bytes가 나온다.
그러므로 20바이트의 공간적인 오버헤드가 발생한다.
TCP에서도 20바이트가 나왔었는데,
그렇기 때문에 헤더만해도 40바이트가 필요하고
전체적인 오버헤드 40바이트 + 알파가 된다.
👆👆 IP Datagram format 👆👆
👇👇IP fragmentation, reassembly 👇👇
mtu(Maximum Transfer Unit)
보내는 사이즈랑, 내 밑쪽, 링크에서 제공하는 최대 큰 사이즈와 차이가 있을 것이다.
이것이 문제가 되게 된다.
링크마다 MTU값들이 다다를 것이다.
그렇기 때문에 상황에 따라, 라우터에 따라
해당 라우터 MTU에 해당하는 만큼 IP 데이터 그램을 쪼갰다가, 합쳤다가 해야하는데,
이를 fragmentation, reassembly라고 한다.
이렇게 합칠 때에는 앞에 헤더에 나와있는 필드들을 참고하여 합치게 된다.
아까 ID와 flag, offset들을 활용하게 되는데,
예를들어 4000 바이트의 데이터그램을 가지고 있고
MTU는 1500바이트이다.
그러면 4000바이트짜리를 1500바이트로 쪼개주어야한다.
20바이트는 헤더이니까 1480바이트가 데이터필드에들어와 있을 것이고
flag값은 1이면 뒤에 단편화된 조각들이 더 있음을 의미
0이면 쪼개져있는 상태긴하지만 자신이 마지막이라는 것을 의미한다.
단편화의 끝을 알려준다.
offset같은 경우에는 쪼개지기전 데이터그램에서 몇번째 offest에 있는 데이터를 가지고있는지를 나타낸다.
상대적인 offset으로 0부터 시작해서
오프셋 단위가 8바이트이기 때문에 8바이트 블락이라고 생각하면된다.
1480을 그래서 8로 나누어진 수인 185를 ++하여 offset의 값을 증가시켜주면된다.
앞에서 헤더인 20바이트 만큼 단편화된 블럭들이 바이트 손해를 봤으니까
마지막 단편화에서는 앞 블럭들 * 20 만큼인 40바이트를 더 보내주면 된다.
그래서 마지막 바이트는 4000 - (1500 + 1500) 인 1000 바이트에 40바이트를 더해준 1040 바이트를 보내주면 된다.
아이디는 다 같다. 이 아이디가 다 같아야 똑같은 데이터 그램에서부터 단편화 된 것을 알 수 있다.
👆👆 IP fragmentation, reassembly 👆👆
👇👇 IP addressing 👇👇
IP 주소는 32비트를 사용한다.
32비트의 ID가 있고 이 같은 경우는 각각의 호스트 또는 라우터 인터페이스에 할당된다.
각각의 호스트도 호스트의 렌카드가 여러개가 꽃혀있으면 여러개의 IP 주소가 있을 순 있다.
여기서 말하는 인터페이스라고 하면, 라우터가 피지컬 링크로 연결되어 있을텐데,
이 연결되어 있는 사이를 이야기한다.
랜선을 꽃을 때 이를 인터페이스라고 생각하면된다.
인터페이스가 여러개인 랜카드가 존재하고 이는 또 여러개의 포트가 존재하게 된다.
라우터 같은 경우에는 일반적으로 굉장히 많은 인터페이스를 갖고 있다.
호스트 같은경우에는 일반적으로 하나혹은 2개정도를 가진다.
일반적으로 집에서쓰는 것은 랜선 1개 꽃기 때문에 1개밖에 없다.
서버같은 경우에는 서버용 랜카드 보면 여러개의 포트가 존재하는 경우도 많다.
이더넷이 우리가 일반적으로 생각하는 랜선과 스위치라고 생각하면된다.
와이파이도 결국에 이 인터페이스에 속한다.
무선 랜이라고 해서 피시나 노트북에 장착되어있어야한다.
직접 꽃힌게아니더라도 그 사이에 일어나는 피지컬링크 사이에서 일어나는,
연결되는 사이지점을 인터페이스라고 한다.
IP주소 같은경우 10진 표기법을 사용한다.
225.1.1.1
예를들어 위와 같이 IP주소는 만들어지는데,
각 .사이 숫자마다 8개의 이진수로 이뤄진 8비트이다.
4부분으로 구성이 된다.
그러면 각각이 8비트씩 사용할 수가 있고
8비트는 256개의 숫자를 표현할 수가 있다.
그래서 0부터 255까지 표현할 수 있다.
그래서 아이피 주소에서 각 파트가 가질 수 있는 최대 수는 255이다.
각 8비트씩 총 32비트로 표현할 수 있다.
인터페이스는 어떻게 연결이 되냐면
결국 유선, 랜선으로 연결될 수 있다.
이더넷 스위치까지 역할을 하고 있는 것이
공유기이다.
그리고 유선 뿐 아니라 무선도 가능하다. 와이파이로
결국에 연결되는 지점들이 존재할 것이다.
이러한 부분들이 다 인터페이스이며,
인터페이스는 물리적인 매체로 연결이 된다.
중간에 라우터가 있고 호스트들 사이에 아무것도 존재하지 않는다고 생각해보자
subnet이라는 게 IP주소에서 중요한 부분인데
subnet은 IP주소를 가지고 있는, 일종의 네트워크가 구성된 것.
보조 네트워크 구성으로, 중간에 라우터 없이 얘네들 끼리만 물리적으로 서로 통신할 수 있는 상태라고 생각하면 된다.
라우터가 존재하지 않아도, 얘네들끼리 커뮤니케이션을 할 수있는 네트워크라고 생각하면된다.
IP 주소가 있으면 ,32비트짜리
32비트 중에 상위 몇비트는 subnet비트 구성하며, 나머지는 host파트를 나타내게된다.
ip주소자체도 약간의 구조화가 있다.
subnet파트를 통해 해당 ip주소가 어떤 subnet에 해당하는지 알 수 있게된다.
호스트를 담당하는 다른 비트들은 subnet부분이 다르다면 호스트 부분이 같아도, 다른 곳을 identify한다.
그래서 서브넷을 조금더 자세하게 보자면,
호스트나 라우터를 인터페이스에서 때어낸다음에 이것들을 생각해보면 된다.
생각을 해보면 서브넷은 어떻게 나타낼 수 있는지
보면 서브넷 마스크라는 게 있다.
223.1.3.0/24
이런식으로 /뒤에 나타는 것들
사우이 몇비트까지가 서브넷을 나타내기위한 비트인지 표현해준다고 보면된다.
위와같은 애가 의미하는 바는 상위 24(8*3)비트, 3번째 숫자까지 233.1.3까지가 서브넷을 나타내는 것이고,
나머지가 호스트를 나타내기 위한 것이다.
그리고 8비트 단위로 나누어 떨어지지 않아도 상관없다
CIDR
인터넷 주소를 할당하는방식에는 8비트 단위로 서브넷 부분을 나눠줘야 하는게 아니라
그런 것에 상관 없이 할당할 수 있는 사이더와 같은 방법이 있다.
이는 Classless InterDomain Routing의 약자이며
x부분, 서브넷 부분에 해당하는 길이를 임의로 설정할 수 있다.
8단위가 아니라, 20이 될 수도있고, 21이될 수도 있고..
실제로 어드레스 포맷이 이 뒷쪽 x까지 포함되어야 하나의 어드레스를 나타낼 수 있다.
실제로 a.b.c.d/x 에서 a,b,c,d가 모두 같다고 하더라도, x가 다르면 다른 서브넷에 다른 호스트를 의미한다.
그래서 x값에 따라서 ip어드레스가 표현할 수있는 것보다 더 많은 것을표현할 수 있다.
1100100 00010111 00010000 00000000
|------------------------------|
여기 까지가 서브넷 부분이고 나머지 9비트가 호스트 부분이라고하면
호스트 부분은 2^9으로 512개의 호스트를 가지는 서브넷을 만들 수 있게 된다.
이 서브넷은 512개의 호스트에게만 아이피를 할당할 수 있게 된다.
아이피 주소를 어떻게 얻을 수 있을까
2개의 관점에서 생각할 수있는데
1. 하나는 호스트의 입장에서 호스트가 처음 네트워크에 들어왔을 때 ip주소를 어떻게 할당받을 수 있는지.
2. 네트워크 관점에서 봤을 때 새로운 네트웤, 서브넷이 추가가 됐을 때 IP주소를 어떻게 할당받을 수 있는지
1. 호스트 IP주소 할당 받는 방법
1-1. 첫번 째 경우에는 호스트는 어떻게 IP 주소를 얻나.
크게는 2가지 방법이 있을 수 있다.
일반 PC에서는 IP주소를 할당할 필요 없는데
서버 환경같은 곳에서 고정IP를 할당 받아사용할 수있는데
시스템 관리자 IP주소를 정해서 그 사람에게 할당해주는 것이다.
이런 식으로 수동으로 할당해줄 수 있고,
1-2. 다른 방법은 DHCP로, Dynamic Host Configuration Protocol의 약자로
자동으로 동적으로 서버로부터 IP주소를 할당을 해주는 프로토콜이다.
새로운 공유기의 새로운 PC를 연결한다든지, 노트북을 연결하든지 할때, 수동으로 IP할당할 필요 없는 것은
DHCP를 사용하기 때문인데, 이는 'plug-and-play' 원리로 작동하기 때문이다.
이는 결국에 내 서브넷에 존재하는 네트워크로부터 ip주소를 얻어온다.
새로운 애가 네트워크에들어와서 합류하려고할 때 새로운 ip주소를 할당받을 수 있어야한다.
만약 어떤 주소를 할당받아 사용하고 있는 중에, 이것을 무한정 쓸 수 있는 것이 아니라, 시간이 지나면 계속 갱신을 해줘야 하는데 이부분도 지원해주어야 한다.
그러나 계속 ip 주소가바뀔 필요는 없다. 연결이 되어 있는 동안에는 똑같은 주소를 사용할 수 있게 해주어야 하고
모바일 유저가 어떤 네트워크에 들어왔을 때IP주소를 할당 받고 나갈 때 회수할 수 있게 해야한다.
모바일 환경에선 네트워크에 들어왔다 나갔다 하는 경우가 많기 때문에
위처럼 호스트에 해당하는 부분이 512개 할당할 수 있다고 한다면 일단 512개한테 할당한 다음은 할당할 IP주소가 없을 테니, 이 부분에 대해 어떻게 회수를 하고 다시 줄것인지 이런 부분을 고려해야 한다.
DHCP가 동작하는 방식은
결국에, 하는 것은 일단
a. DHCP 역할을 하는 서버를 찾아야 한다.
b. 서버를 찾는 메시지를 브로드캐스팅(서브넷에 포함되어 있는 모두에게 알린다)
c. 그러면 여러개의 호스트들, 그중 DHCP 서버도 있을 텐데, DHCP 서버는 이 메시지를 보고, 메시지 센더한테 DCHP IP주소를 정해서 사용가능한 IP주소를 알려준다.
d. 그런 다음 메시지 센더 호스트가 제안을 메시지로 받게 되고,
e, 사용할 수 있는 IP 주소를 알게되고, 이를 사용할 여부를 DCHP 서버에게 다시 리퀘스트를 보내고,
f. 이 부분에 대해 DHCP는 ACK를 준다.
DHCP client-server scenario

위와 같은 네트워크가 있는 상황에서 오른쪽의 서브 네트워크에 DHCP 서버가 존재한다.
DHCP 서버도 아이피 주소가 할당되어야 한다.
이상황에서 기본적으로 라우터와 DHCP 서버가 같이 존재한다. 따로 구분되어 있지않고 통합되어 있다고 생각하면된다.
집에서 사용하는 공유기에도 DHCP 서버 역할을 하는 기능이 포함되어 있다.
DHCP 서버는 해당 서브넷에 해당하는 것을 책임을 지게 된다.
이 상황에서 새로운 노트북을 네트워크에 연결하고자 한다고 한다면
IP 주소가 필요할 것이다.
어떤 식으로 IP주소를 얻어오냐면
DHCP 서버와 클라이언트(개인노트북) 이 있다면
1. DHCP Discover
server <- client
이 클라이언트가 DHCP 서버가 존재하는지 확인하는 DHCP discover 메시지를 브로드캐스팅을 한다.
브로드 캐스팅은 사실 225.225.225.225 주소가 브로드 캐스팅에 사용하는 ip주소이다. 이 아이피 주소로 보내면
내 서브넷 내의 모든 애들한테 이 패킷이 전달이 된다.
그래서 클라이언트가 전체 내 서브넷에 있는 애들한테 DHCP 서버를 찾고있음을 알린다.
2. DHCP Offer
server -> client
그러면 DHCP 서버가 이 메시지를 받으면 다시 자신이 존재함과 사용할 수 있는 IP 주소를 브로드캐스팅을 통해 알려준다.
그리고 YOUR IP ADDRESS를 알려준다. 그리고 LIFE TIME이라고 해서 이주소를 한번 할당받았을 때 얼마나 사용할 수 있는지에 대한 내용을 담는다. 그래서 이를 3600초라고 되어 있다면 3600초 이후에서는 DHCP서버가 다시 회수할 수있다.
+
어쨋든 이 위의 2과정인 DHCP Discover, DHCP Offer 이 과정은 생략이 될 수 있는데,
클라이언트가 처음 들어온게 아니라 이미 할당받았언 IP 주소가 있을 수 있다.
이런 경우는 위 2과정이 생략될 수 있다.
일반적으로 집에서 노트북이나, 학교에서만 쓴다고 하면 똑같은 IP 주소를 써도 되기 때문에,
이미 알고있는 IP 주소로 사용할 수 있다.
3. DHCP request
server <- client
클라이언트 쪽에서 다시 요철을 한여
받은 IP 주소를 사용할 것을 서버에게 알려준다.
이 때에도 브로드 캐스트를 하게되고 이 때에도 자신이 사용할 IP 주소와 여러가지를 담아 보내게 된다.
+
왜 1,2,3 과정 모두 브로드캐스트를 사용하냐면
이 해당 서브넷에 DHCP 서버가 하나만 있다는 보장이 없기 때문
여러개가 있을 때 클라이언트가 어떤 애를 선택할지모르고
서버 입장에서도 클라이언트가 자신의 것을 선택했는지 알기 쉽도록하기 위해서 브로드캐스팅을 한다.
4. DHCP ACK
server -> client
어던 아이피 주소를 사용할지 알려주고 확정된다.
DHCP 가 당당하는 일은
IP 주소만 알려주는 것이 아닌 더 많은 내용들을 담당한다.
다양한 정보들을 클라이언트에게 알려주는데,
1. 첫번째 라우터의 주소를 알려준다.
그래서 클라이언트가 외부로 인터넷상으로 패킷을 보내기 위해서는 어떤 라우터한테 보내야하는지를 알려준다.
2. DNS 서버에 이 IP 주소와 이름 이런 것들을 알려주기도 한다.
3. 네트워크 마스크 /X 같은 것들도 알려줘서 IP 주소 중에서 어떤 부분이 네트워크 부분이고,호스트 부분인지 알수도 있도록 마스크를 알려준다.

위 그림과 같은 상황이 일반적인 상황으로 라우터와 DHCP 서버가 함께 있는 것
이런 상황에서 새로운 노트북이 연결되었다고 가정하면 그러면
처음엔 DHCP 를 써서 IP주소를 얻으록할 것이다.
DNS 서버의 이름과 주소도 함께
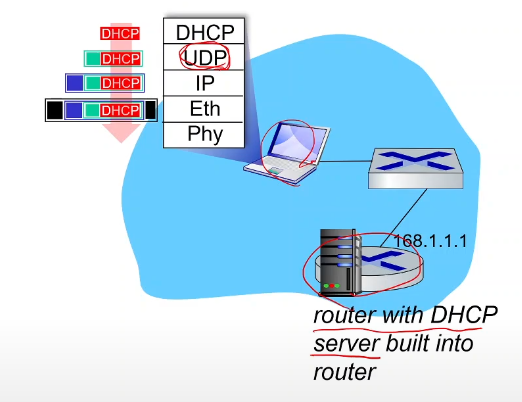
그러면 일단 DHCP 리퀘스트 메시지, 이미 IP 주소를 알고 있다는 가정하에,,
이 리퀘스트 메시지를 보내면, 밑에 트랜스포트 계층에서 UDP 레이어를 써서 보내게 된다.
UDP는 연결이 따로 필요없기에 그리고, 브로드캐스트를 하기위해서는 UDP를 사용한다.
그래서 UDP를 사용해서 레이어를 따라 이 메시지를 보낸다고 생각하면 된다.

라우터를 따라서 스위치, 라우터를 따라 DHCP 서버에 도착을 하게 된다.
여기서 받은 것을 하나씩 까서 DHCP 메시지를 확인하게 된다.
여기서 DHCP 서버가 다시 ACK를 보내게 된다.
ACK를 줄때 클라이언트 IP 주소 뿐아니라, 첫 라우터의 주소, DNS 서버의 이름과 주소 등도 여기에 포함이 된다.
그래서 이부분을 다시 클라이언트가 받아서 DHCP 메시지를 분리를 한다.
이 DHCP 메시지 안에는 IP 주소, DNS 서버 관련 내용, 첫라우터 주소 등이 다 담겨있다.
2. 네트워크, 서브넷 파트는 어떻게 얻은 수 있는지
ISP(Internet service provider)한테 할당이 된 것에서 일부를 얻어온다고 생각하면 된다.
ISP 한테 200.23.16.0/20 이라는 IP 대역이 할당되었다고 가정해보자.
20비트이기 때문에 밑 12비트가 호스트 관련 비트로 남아 있다 20비트는 서브넷을 나타내는 애들이다.
그러면 바로 쓰는 것이 아니라 다시블락단위로 분리를 하게 된다.
예를들어서 3비트로 쪼개게 되면

000, 001, 010, ..., 111 이렇게 블럭이 있고, 이 블럭을 기준으로 나눈다면,
2^3 인 8개의 블럭으로 나누어 사용할 수 있다.
이렇게 되면 마스크는 기존 20에서 3비트를 더한 23이 될 것이다.
3비트를 더 써서 서브 서브넷으로 나눌 수 있게 된다.
이렇게 나누면 사용할 수 있는 호스트의 수는 조금 줄어들게 될 것이다.
이런식으로 블락을 나눠서 할당을 하게 되면 실제 라우팅 정보를 다른 라우터와 공유할 때 도움이된다.
예를 들어
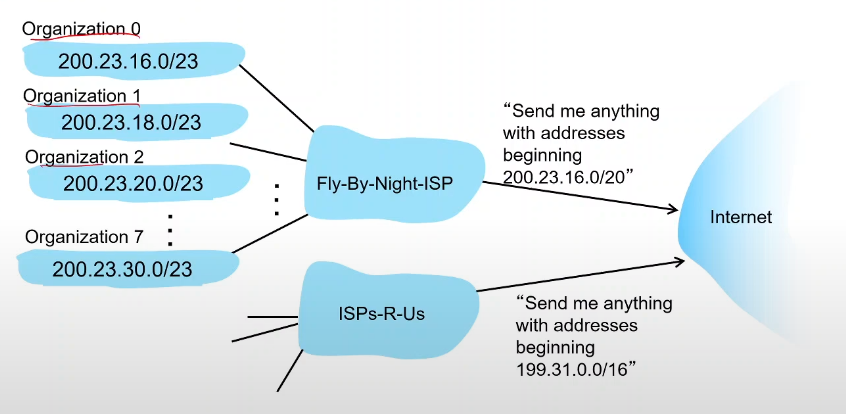
위 그림과 같이 다른 기관들이 여러개가 있고 ISP가 2개가 있다고 하자
이 상황에서 위 ISP는 네트워크 상에 200.23.16.0 이고 서브넷 마스크가 20인 아이피 주소에 해당하는 것은 이 ISP를 통하게 되고
다음 ISP는 199.31.0.0 이고 서브넷 마스크가 16인 것은 아래 ISP를 거치게 할 수 있다.
이러한 상황에서 만약에 기과 1이 위 ISP를 쓰다가 아래 ISP로 넘어가게 된다면, 즉, 다른 ISP를 쓴다면
이동을 하고, 원래 아래 ISP 주소가 선택하고 있는 아이피 주소 199.~을 바꾸지 않고도 기관 1이 사용하고 있는 아이피 주소를 추가하여 알려줄 수 있다. 200.23.18.0/23도 아래 ISP로 오도록 요청을 바꿀 수 있다.
그러면 ISP는 어디서 주소 블락을 얻어 오는 것이냐
이 역할을 하는 것이 ICANN 이다.
DNS배울 때 루트 도메인을 관장하는 기관이었다.
이것이 IP주소 할당도 처리해준다.
만약 이 ICANN이 5개의 등록기관을 가지고있다고 있다고 생각하면된다.
그리고 이 ICANN은 DNS 관리도 맡아서진행하고 있다.
결국에는 이 ICANN이 ISP들한테 할당을 해준다고생각하면된다.
32비트 주소로 충분히 어드레스 할 수 있나?
근데 실제로는 이 ICANN에서는 모든 IPv4 주소를 다 할당을 했다. 그래서 더이상 할당을 해줄 ip는 없다고 한다.
근데 어떻게 계속 IP주소를 사용할 수 있을까?
NAT라는 기술덕분에 가능함.
NAT이 효율적으로 동작하기 때문에 IP주소가 부족하지 않고 정상적으로 네트워크가 정상적으로 동작할 수있음
IPv4는 32비트, IPv6는 128비트로 주소가 훨씬 많다.
그러나 이것이 잘 전환이 안되는 것은 NAT라는 기술이 잘동작하고 있기 때문이다.
👆👆 IP addressing 👆👆
'개발👩💻 > 네트워크' 카테고리의 다른 글
| 12-1:Network Layer: control plane (0) | 2021.06.02 |
|---|---|
| 11-2:Network Layer: Generalized Forwarding (0) | 2021.05.28 |
| 11-1:Network Layer: IP: the internet protocol (0) | 2021.05.28 |
| 9-2: TCP Congestion Control (0) | 2021.05.09 |
| 9-1:Principles of Congestion Control (0) | 2021.05.09 |



