TCP Congestion Control 방법
1️⃣ AIMD (구버전) : 톱니바퀴
timeout, new ACK 이벤트 발생 시 변하는 상태
slow start, congestion avoid, fast recovery
AIMD 방식 TCP 버전
TCP Tahoe (구버전)
TCP Reno (신버전)
2️⃣ CUBIC (신버전) : 3차 함수
1️⃣ AIMD (구버전) : 톱니바퀴
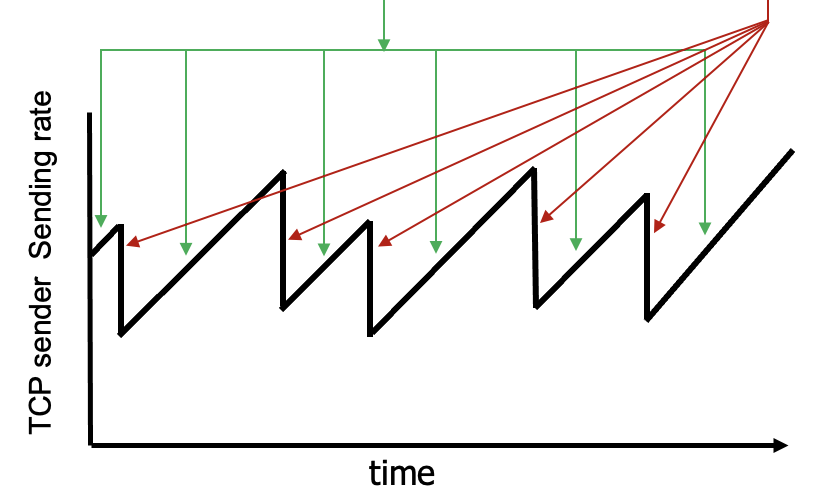
접근 방식:
congestion 발생해서 패킷 로스가 발생할 때까지 보내는 쪽 속도 계속 증가시켜가다가,
패킷 로스가 발생하면 줄여가는 방식
이름에서 나와 있다 싶이
증가시킬 땐 선형으로 증가시키고
감소시킬 땐 빠르게 증가시킨다.
이 형태는 증가할 땐 + 로 증가, 감소할 땐 * 로 감소하는 것과 같다.
그리고 점진적으로 sending rate를 증가시키는데,
1씩 증가시킨다고 할 때 1은 1MSS을 나타낸다.
1MSS 는 TCP 기준으로 1RTT당 1460bytes이다.
이를 1RTT 내에서 패킷 로스가 발생할 때까지 MSS를 증가시킨다.
이와같은 방식을 통해서 적절한 bandwidth를 찾아간다.
AIMD는 비동기, 분산 알고리즘에서 사용되어 왔기에 여기서도 사용한다.
네트워크 범위로 혼잡흐름 최적화에 도움을 줄 수 있고, 안정적이다.
congestion window

초록색: ACK 받은 애들
노란색: segment 보냈지만 아직 ACK 못받은 애들 (= In-flight 상태: 링크 상 아직 전송 중)
+ 노란색 끝부분: 마지막으로 보낸 바이트
파란색: 윈도우 안에 있지만 아직 사용하지 않은 애들. 얘들이 있으면 사용할 수 있는 부분이 남아있는 거라 TCP계속 전송가능
노란색 + 파란색 : cwnd (current window)
가장 마지막에 보낸 바이트 - 가장 마지막에 받은 ACK <= cwnd
= 결국 위 식은 노란색 부분을 의미한다(보냈는데 아직 ACK 못받은 애들)
이 노란색은 항상 cwnd보다 작거나 같아야 한다.
이 cwnd는 동적으로 congestion 상황에 맞춰 값을 바꾸면서 조절한다.
이 cwnd는 한번에 보내는 패킷의 양과도 같은데 얘네를 보내고 1RTT동안 기다리니까 (1RTT 내에 왔다 갔다)
cwnd / RTT는 현재 TCP rate를 알 수 있다.
TCP rate ~= cwnd / RTT (bytes / sec)
그리고 ACK 온만큼 또 cwnd를 전진한다.
Tehoe Reno
테호는 slow control을 할 때
ssthresh를 만나면 MSS를 다시 1로 세팅하고 2^n씩 증가하는 방법
레노는 slow control할 때
ssthresh를 만나면 MSS를 1/2로 줄이고 선형으로 증가하는 방법
레노가 더 효율적으로 throughput을 사용함

x 축은 RTT를 의미한다.
그러니까 RTT가 지남에 따라 ssthresh까지는 윈도우 사이즈가 2^n씩 증가하다가 ssthresh를 만나면
여기서부터 선형으로 증가한다.
그리고 12인 상태에서 패킷로스가 일어났다면,
로스가 일어난 지점을 기준으로 1/2을 해서 새로운 ssthresh 기준을 만든다.
이 ssthresh를 기준으로 다시 선형으로 증가하는 게 레노 방식이고
그냥 1MSS로 초기화하는 애가 테호 방식이다.
태호는 1MSS로 초기화하고 새로운 ssthresh까지 2^n씩 증가하다 ssthresh만나면 선형으로 증가한다.
Slow start, congestion avoid, fast recovery
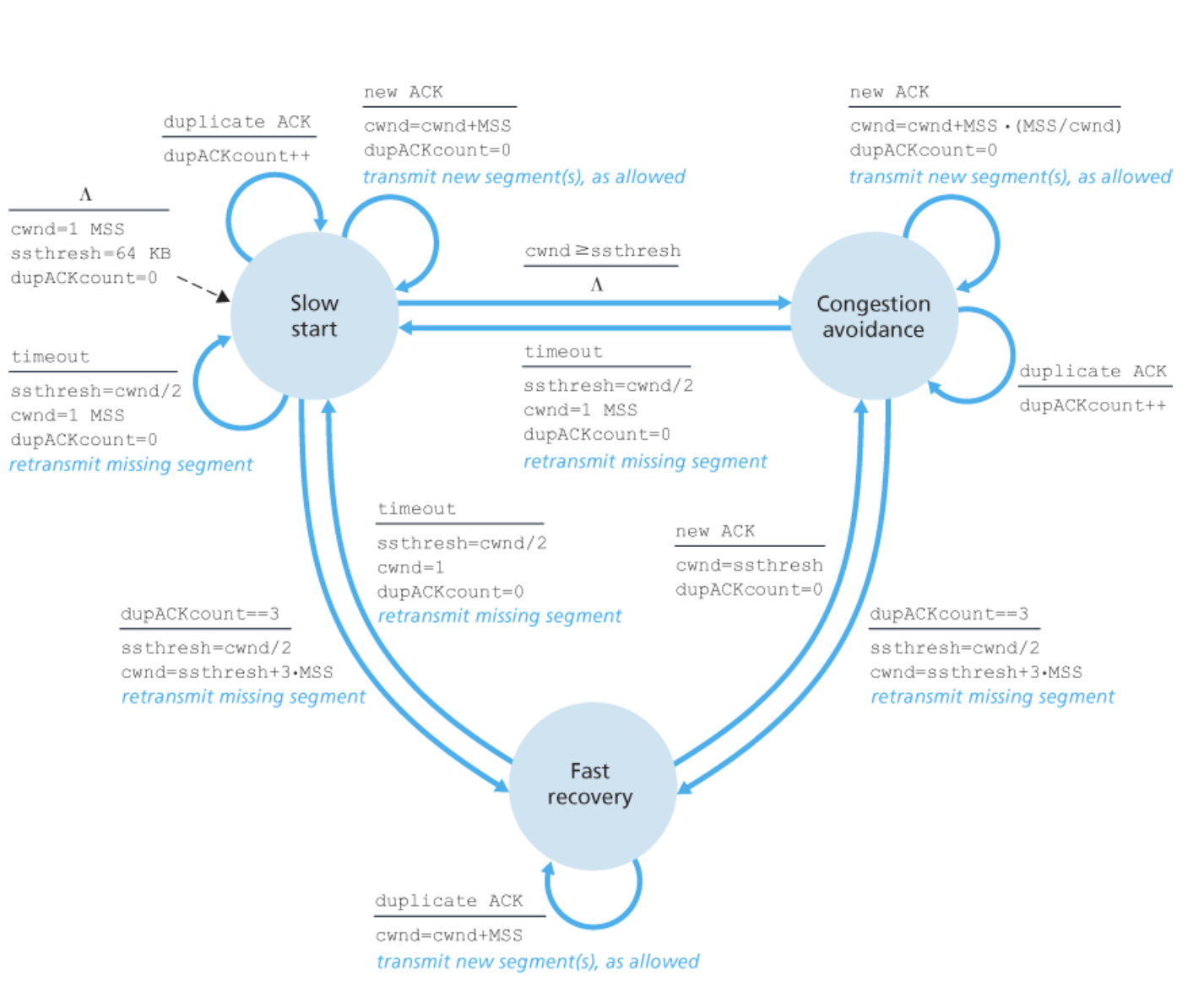
slow start는 빠른 증가 위한 state
① 초기화를 하고
② 새로운 ACK를 받아 cwnd를 증가시키고 👈
② - 1 ACK를 받았으니 cwnd를 2^n만큼 증가시켜야한다.
② - 2 새로운 세그먼트 전송
③ 중복된 ACK를 받아 dup-에 더하는데
③ - 1 dup-이 3이되면 fast retransmission을 하기위해 fast recovery state로 보낸다.
③ - 2 이렇게 보낼 때는 보내는 rate에 문제가 있는 것이기 때문에
sstresh를 cwnd/2 (걍 sstrech를 반으로 줄이는 거임) 해준다.
그리고 cwnd는 ssthresh + 3 해주는데, 이건 레노가 줄어든 ssthresh 부터 다시 시작하는 거 +
retransmission으로 3개 다 보냈으니 그거 더해준 것
③ - 3 그리고 로스세그먼트 재전송
④ cwnd가 너무 커져서 ssthresh를 넘으면 선형적으로 증가시키기 위해 congestion avoid로 이동
④ - 1 그리고 로스세그먼트 재전송
congestion avoidance는 선형적 증가 위한 state
① 새로운 ACK를 받으면
① - 1 1MSS만큼만 증가시킨다.
① - 2 새로운 새그먼트 전송
② 중복된 ACK 오면 dup- 증가 근데 이제 이게 3이되면 fast retransmission위해 fast recovery로 보낸다. 여기는 slow start ③과 동일
③ dup-이 3이 되기 전에는 fast re- 할 수 없으니까 timeout만 일어남 이렇게 timeout일어나면 slow start로 보냄
③ - 1 rate에 문제 있는 것이므로 ssthresh 를 반으로, cwnd = 1 MSS (테호는 이렇게, 레노는 new ssthresh 부터)
③ - 2 재전송
fast recovery는 3 dup-으로 fast retransmission state
① dup- 처리된 걸 받아서 cwnd에 +1 MSS 증가, 재전송 (선형증가)
② 새로운 ACK가 오면 (여기도 혼잡했던 곳) 선형적 증가를 위해 congestion avoidance로 이동
③ timeout일어나면 ssthresh 반으로 줄이고, 태호 방식으로 cwnd = 1, 재전송
2️⃣ CUBIC (신버전) : 3차 함수
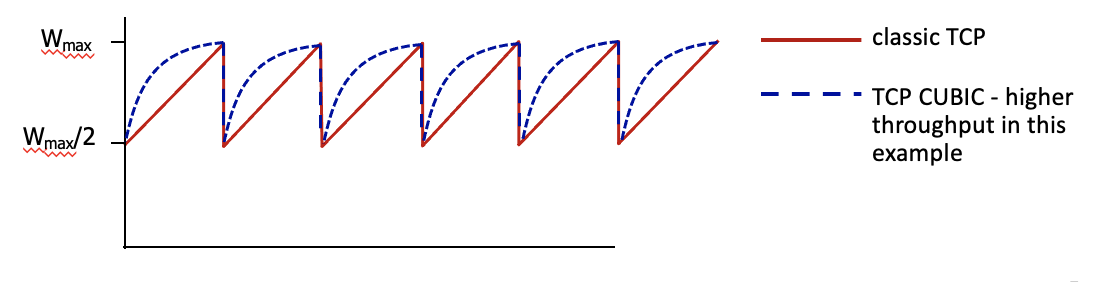
wmax는 congestion loss 발견된 sending rate이다.
중요한 건 병목 링크는 뭘해도 그렇게 변하지는 않는다는 것이다.
즉, 바쁜애는 계속 바쁘고, 한가한 애는 계속 한가함
=> 잘 바뀌지 않는다.
어쨋든 우선 큐빅방법은 선형적으로 증가했던 전통 TCP를 곡선으로 증가시켜, 선형보다 더 효율적으로 throughput을 사용할 수 있도록 한다.
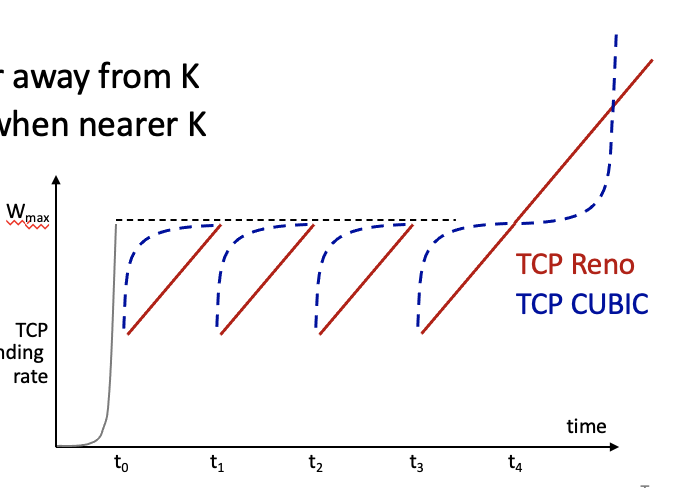
이 곡선 함수는 wmax와 멀수록 빠르게 가까울 수록 느리게 증가하는 게 포인트이다.
그럼 cwnd가 wmax와 같아지는 시점이 언제인지 예측할 수 있어야 하는데,
cwnd가 wmax에 도달하는 시점을 k라고 한다.
이 k는
앞서말한 병목링크 변하지 않는 것에서 알 수 있듯이. 이전에 패킷로스일어났던것으로
다음 패킷로스도 충분히 예측할 수 있고 이를 예측하는 방법이다.
패킷로스가 일어나는 링크는 항상 일어나고, 비슷한 지점에서 일어난다.
이런식으로 튜닝가능하다.
이 큐빅방법은 리눅스에서 default 값으로 사용하고 있는 가장 인기있는 버전이다.
'개발👩💻 > 네트워크' 카테고리의 다른 글
| 12-1:Network Layer: control plane (0) | 2021.06.02 |
|---|---|
| 11-2:Network Layer: Generalized Forwarding (0) | 2021.05.28 |
| 11-1:Network Layer: IP: the internet protocol (0) | 2021.05.28 |
| 10-1:Network Layer: Data Plane (0) | 2021.05.27 |
| 9-1:Principles of Congestion Control (0) | 2021.05.09 |



